
The Salesforce team is looking forward to meeting you remotely at PyCon 2021! In the meantime, check out this case study on how they solved the challenge of assisting customer service agents in finding answers to customer problems.
Problem Statement and Background
The problem we are tackling here is assisting customer service agents in finding answers to customer problems accurately and fast.
To answer customer questions, customer service agents typically rely on Information Retrieval (Search) systems fetching data from heterogenous data sources. These customer questions are often long text and not well-suited for a search system to handle as-is. To that end, we built a content-based recommendation system that matches incoming customer questions, in the form of a customer case or ticket, to the knowledge article that will help address the customer issue.
Approach
The system we built machine learns on a customer’s data corpus and returns the best matching articles when customers ask their questions through incoming tickets, also known as cases.
The system can be visualized as consisting of a training flow and a serving flow.
The training flow begins with an orchestrated data ingestion from the system of record to a data lake where we can perform feature engineering and model training related tasks. The feature engineering phase performs natural language processing (NLP) extraction on the corpus of historical questions and the knowledge articles corpus of the customer. The model training itself consumes the computed features and, using supervised training techniques, learns the feature weights or, more simply, fits the model on the customer’s dataset. This trained model is then evaluated and compared against existing trained models. Finally, the trained weights are sent back to the serving flow for responding with answers to incoming customer questions.
To handle the cold start problem, we have two levels of models: a global model that is trained on a generic dataset and an org-specific model that is trained on the customer’s dataset and is expected to be superior to the global one. However, the global model plays a key role in helping orgs that get started when they don’t initially have a critical mass of data for us train a model on. They eventually get an org-specific model in subsequent re-training as their dataset becomes richer.
In the serving flow, we pairwise compute the feature values using the learnt weights for the incoming customer question and each candidate article and select the top k scoring candidates as final results.
Now let’s take a closer look at the system architecture.
System Architecture
As we highlighted above, there are two main parts of the system – serving and training.
Serving flow
Candidate Generation
Content-based matching and ranking
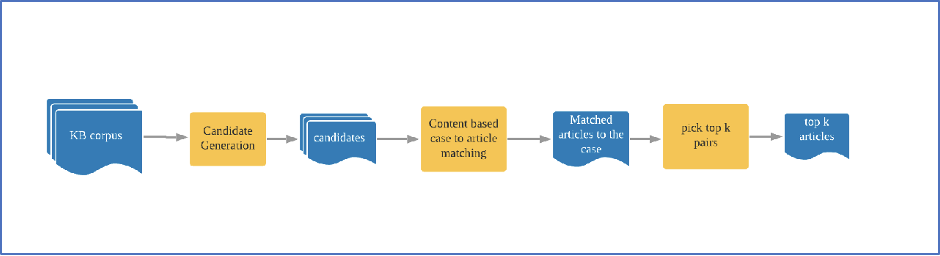
Fig 1: Serving time flow for the Content based recommendation system
- Phase 1: Candidate generation
Candidate generation consumes a large corpus of a customer’s knowledge base articles and produces a much smaller corpus for the next phase. We rely on NLP techniques like entity recognition, noun detection, intent detection, and additional keyword extraction to generate a representative query. These formulated queries are applied against our Information Retrieval (Search) systems to select a subset of the corpus that contains article(s) to address the customer problem at hand.
- Phase 2: Content-based matching and ranking
In the content-based matching and ranking phase, we perform pairwise feature generation for every candidate article/document against the incoming query (the customer request). The computed feature values are then further used to compute the pairwise match probabilities using the weights learnt in the model training phase. From there, we pick the top articles ordered by match probabilities.
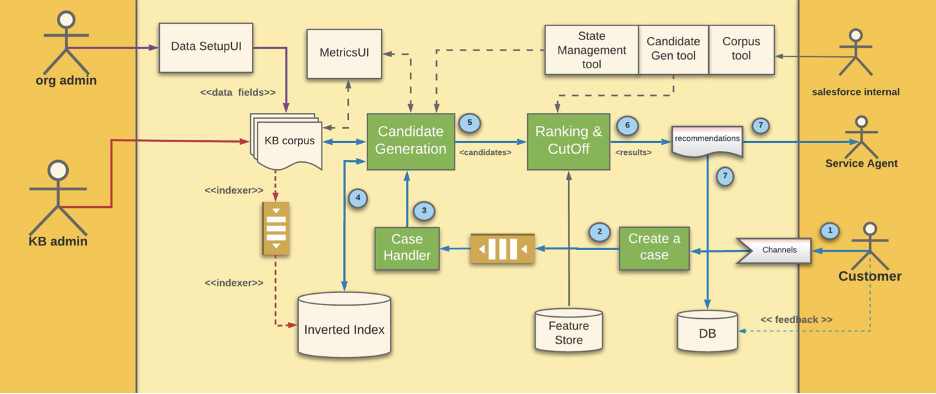
Fig 2: The diagram highlights the serving flow and how different user personas interacting with the system
Model Training flow
The Python language and supporting frameworks provide a comprehensive ecosystem for data processing and integration with frameworks like Apache Spark. Our data processing and model training pipeline consists of Python/PySpark, along with Scala, bundled in a Docker image.
We use Python throughout the pipeline for:
Data Filtering and Cleansing
Feature Computation
Model training, model evaluation and model comparisons based on metrics
Data quality and model quality metrics (computation and comparison)
CI/CD pipeline automation
The diagram below gives an overview of how the auto ingestion flow pulls data from the system of record (customer org) and applies that in the training pipeline. Feedback from the customer actions is directed back to the data store, which is leveraged in the feedback loop.
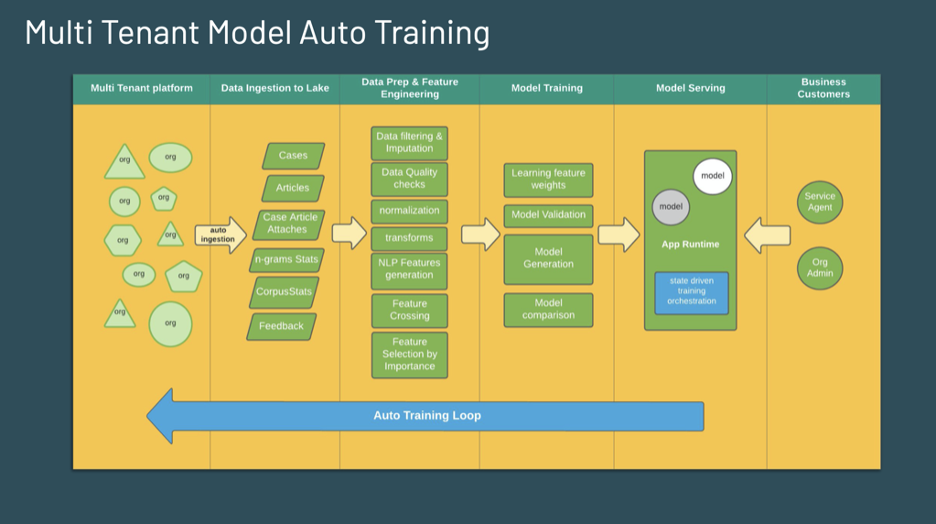
Fig 3: An overview of the auto ingestion flow
Pre-ingestion computation
We use numpy and pandas libraries for feature generation before leveraging them in the model training flow.
Model Training
PySpark provides an easy way to train one of our simpler logistic regression classifier models, like in this example:
from pyspark.ml.classification import LogisticRegression
...
final_estimator = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
train_model = final_estimator.fit(train_df)
...
During training, it is common practice to implement K-fold Cross-validation and Grid Search. PySpark provides sub-modules for both of them as well. To build a parameter-searching grid, we can use the ParamGridBuilder() sub-module and pass the parameter map into the CrossValidator() like in this example:
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
param = ParamGridBuilder().build()
cv = CrossValidator(estimator=pipeline,
estimatorParamMaps=params,
evaluator=evaluator,
numFolds=...)
Model Evaluation
For model evaluation, we rely on the following key metrics:
Precision (Positive Predictive Value)
Recall (True Positive Rate)
F-Measure
Receiver Operating Characteristic (ROC)
Area Under the ROC curve, Area Under the Precision Recall Curve
from pyspark.mllib.evaluation import BinaryClassificationMetrics
...
predictionWithLabels = ...
# Instantiate metrics object
metrics = BinaryClassificationMetrics(predictionWithLabels)
# Area under precision-recall curve
print("Area under PR = %s" % metrics.areaUnderPR)
# Area under ROC curve
print("Area under ROC = %s" % metrics.areaUnderROC)
...
Model Deployment
For Python-specific packaging, Python whl bundling is the preferred way. A Python .whl file is essentially a ZIP (.zip) archive with a specially crafted filename that tells installers what Python versions and platforms the wheel will support.
Our Docker-based deployments ensures we are cloud agnostic for bundling all our dependencies, both Python and jars.
In the diagram below you can see how the Developer or Machine Learning Engineer can continuously update the training container codebase and the rest of the process is automated until the point of deployment to production environments.
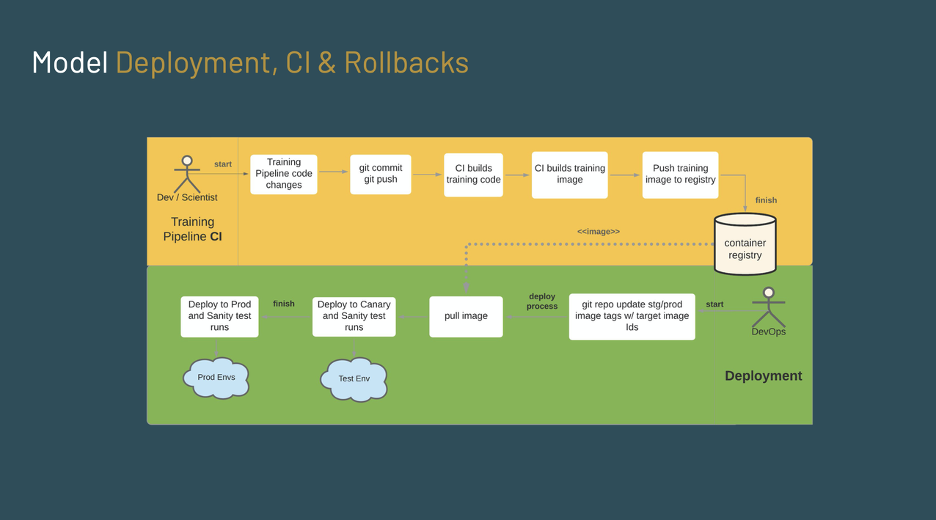
Fig 4: The diagram shows the process for deployment, continuous integration, and rollbacks.
And here is a zoomed-in view of the training container and how the trained model is exposed through serving endpoints.
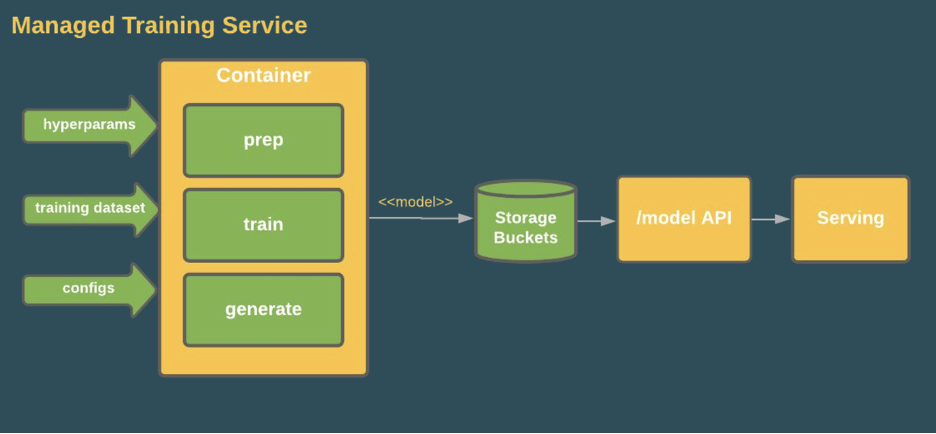
Fig 5: A closer look at the training container and its serving endpoints
Closing thoughts
As with any project, we faced some challenges.
Respecting Customer Data
We place a high priority on respecting customer privacy and adhering to compliance regulations, so there were extra challenges when it came to handling encrypted data at rest and in motion, ensuring data freshness, and navigating circumstances where there was too sparse or too dense data.
Non-Standard Datatypes
The Salesforce platform is extremely customizable, which is a great thing for our customers but meant that we had to make sure our model could handle many custom, non-standard fields and datatypes.
Siloed Data
We do not share datasets across customers’ organizations, which can make it challenging to provide a big enough dataset for training. There are a few thousand training jobs we run in parallel to train the recommendation system model. This is different than a consumer space where generally we have a shared model on a larger dataset.
Training serving skew
The features used during training and serving can change over time, adding to inconsistencies in the model metrics. This is one of the known issues that we had to focus on during model training.
Cold start problem
This is another common problem that we also faced. When a new customer onboards, they generally don’t have enough data to have the model trained on. So, we tackled this by providing a generic model while their datasets get to a point of critical mass for us to get them a custom model.
Our takeaways from this project can be broadly applied. For one, we learned the value of starting small, shipping frequently, and iterating. Starting with simple interpretable models will help you debug. Time to resolution of issues is extremely important when you’re getting started. Then, scale model learning to the size of your data; data size will influence the type of model architecture you choose. We place a high value on our system’s observability, and we also prioritized data privacy over model quality. We’ll never regret putting customer trust first!
Comments